io_uring is not an event system
I’ve been hearing about io_uring on and off for the last couple of years. Its a relatively new technology in Linux to allow high-performance IO with very few overheads.
Whenever its been mentioned, its usually been presented as a new alternative to select, poll and epoll. This led me to believe that it was just the next iteration of those facilities, which is to say, another facility to inform a program that something has happened on a file or network socket or whatever, so that it can take action. In other words, and incremental improvement, presumably with fewer overheads, but otherwise just more of the same. Which is great, but boring for me: I understand the concept well, but these days I run other peoples’ software and don’t really write my own, so I haven’t cared too much about the finer details.
Then last week I was watching Brendan Gregg’s LISA21 talk “Computing Performance: On The Horizon”, and this slide caught my eye:
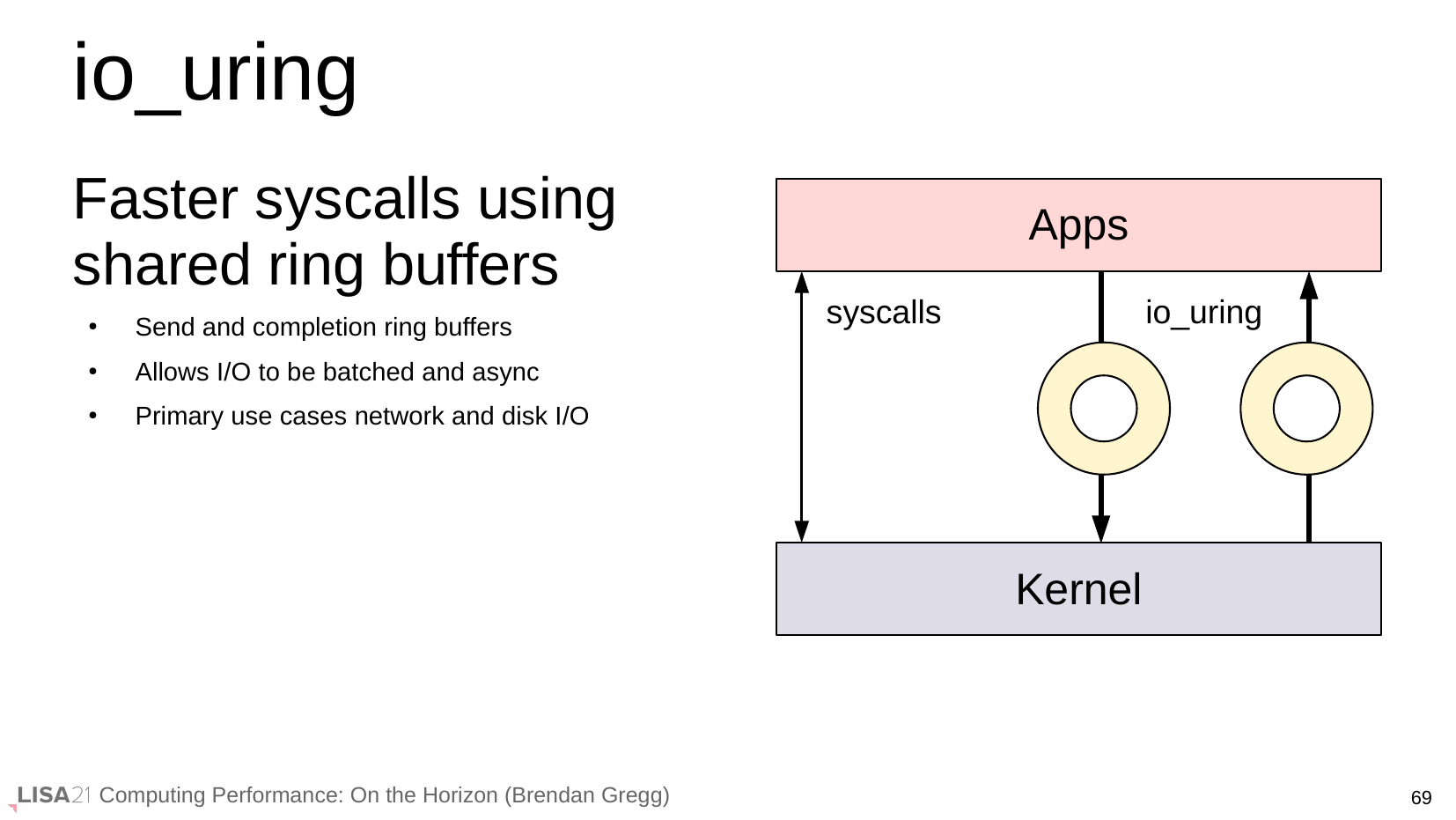
I don’t know if it was the promise of “faster syscalls” or the diagram, but something told me there was more to io_uring than I realised. I didn’t know what, but enough that I thought I figured I should try it out.
Thinkng it was a new kind of descriptor readiness facility, I thought to just write a dumb multiuser telnet chat server. This kind of program was bread-and-butter for me once, long ago - writing MUD-like chat servers was where I got my start learning C, UNIX and network programming. As it turns out though, that was too long ago, and most of the interesting information had fallen out of my head.
So, I devised yoctochat: a sort of shape for the simplest possible chat server, implemented multiple times using a different descriptor readiness facility each time. I started with one for select, then one for poll. The epoll version tool a little longer because I’d never used it before, but since its more of the same, the shape was basically the same.
With those out of the way, and a clear understanding of what these programs are, even are, a couple of days ago I started on yc_uring.c. After a few abortive starts I started to get a feel for things and it began to take shape. Later, I stopped to do some house chores and was thinking about the shape of the program I was building, and it hit me:
io_uring is not an event system at all. io_uring is actually a generic asynchronous syscall facility.
And now suddenly I see what the fuss is about!
The classic UNIX IO syscalls (eg read()) are all synchronous, and blocking. You call them, and your program goes to sleep until the thing you requested occurs. In the case of read(), that’s “data arrived”.
The obvious problem is, what do you do if you want to read() from more than one thing at a time? What if we block while trying to read from one thing, and then something happens on the other one thing? It might wait forever!
There are awkward solutions like setting an alarm to interrupt the operation so we can move to the next thing, or using “non-blocking” mode, but both have their problems. The only thing that works is to use a descriptor readiness facility such that we can say “wake me when any of these things have stuff to be read, and then tell me which ones the are”. Once that fires, we go through the things it reported, and call read() on each of them, knowing that they won’t block because they all have stuff waiting.
select() is the original UNIX facility for descriptor readiness. It works fine for small numbers of things, but doesn’t scale very far. poll() was created to address some of its problems, but added some of its own. Most UNIXlikes went their own way with improved systems after this, most notably Linux’s epoll and FreeBSD’s kqueue, which have been extended over the years the be the weapon of choice to date. They are all conceptually the same as the old methods though: ask the system to wake the process when something happens to any number of interesting things, so the process can then go and take action each one.
io_uring takes a different approach though. It goes right back and looks at the original problem with fresh eyes, and says what if, instead of the kernel telling us when something is ready for an action to be taken so that we can take it, we tell the kernel what action to we want to take, and it will do it when the conditions become right.
This is almost always what we want anyway. In the traditional model, the user program calls into the kernel to ask it to tell it when something is ready, and then immediately afterwards calls back into the kernel to make it perform the action. The user program doesn’t do anything in between, so if those two calls can be combined and submitted to the kernel, the user program doesn’t have to get involved at all.
Its operation is fairly straightforward too. All it does is split a call in half - you make a request, and some time later, its done and you get the results back. While the requests and responses are encoded differently (the call name and arguments are in a memory buffer that you submit, rather than an actual function call), its the same effect - the kernel is asked to do something on behalf of the program.
The whole thing works with a pair of queues: the submission queue, where you put requests for service, and the completion queue, where you find completed requests with their results.
The whole “ring buffer” and “uring” thing? They’re really just implementation details, which probably goes some way to explain my confusion all this time: every damn description gets excited about ring buffers, so I thought they were actually an important part of it, when really it feels a lot more like just calling a remote API.
And since just another way of doing syscalls, it works for basically everything, including file IO which has traditionally been hard to do asynchronously. So it has the potential to make a lot of programs much simpler.
I was very impressed once I figured it out, and I’m looking forward to seeing it in more of the programs I use. I just wish it had a bit better documentation around it, because I wonder how many others haven’t yet looked at it because they thought it was something different? Who knows!