A data corruption bug in OpenZFS?
The Thanksgiving long weekend (23-26 November) in 2023 was an interesting one for OpenZFS, that I managed to land myself in the middle of. The short version of events is that an apparent silent data corruption bug was discovered, which is kind of the worst case scenario for a data storage system.
It was a pretty intense few days for me, initially one of a few people looking into the bug, and then later being involved in working out a fix, talking to downstream vendors, responding to private and public messages with users, my own customers and the press, and doing damage control. It was mostly done with by the end of the weekend, though took a couple of weeks to mop up, and overall I’d rate it a qualified success for the project.
I’ve been writing this post on and off since then. A lot happened, and I have a lot of thoughts, and I wanted to get them all down, but it got too much. So this post just covers the bug itself, and I’m hoping to write more about the fuzzier stuff soon. If you’re reading this months later and I still haven’t, maybe ping me and remind me that I promised!
SPONSOR MY WORK
Use OpenZFS? Like this post? Help out by sponsoring my OpenZFS work!
Free filesystem lesson
To understand what happened, you need to know a little bit about OpenZFS internals. If you have been paying attention to the whole kerfuffle, then you might recognise some of the moving parts as we go along!
What is a file, really?
If you lift the lid on a OpenZFS filesystem (or volume!) you’ll find that OpenZFS is an object store. The top-level object is called an “object set” (or just “objset”), and can be thought of as just a giant array of objects. In turn, each object has two parts:
- the “dnode”, which is a kind of metadata header that describes the object’s type, size, etc, and carries a pointer to its first data block
- the object data, which is a tree of blocks, either an “indirect” block that just points to more blocks, or a “data” block, which is, well, data.
For the purposes of this discussion, we can consider a simplified view of the world, with the objset at the top, a list of dnodes, each with a count of attached data blocks, and then a list of data blocks.
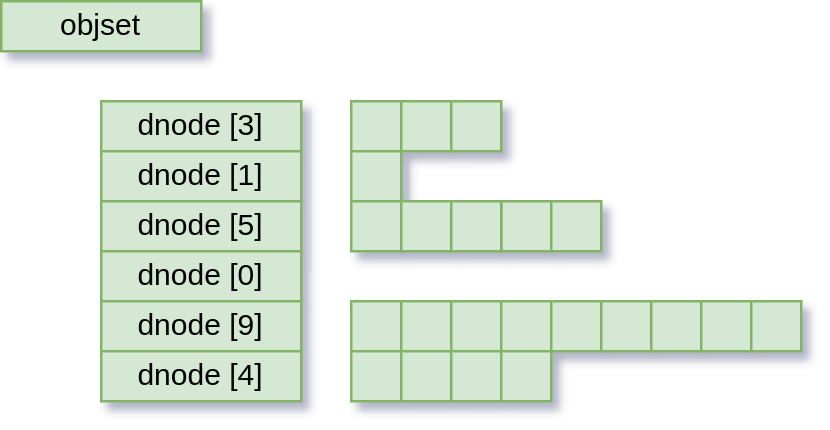
There isn’t more to it in concept. Higher-level filesystem concepts are just built out of more objects, for example, a directory is just a special kind of object (internally called a “ZAP”) that is just a dictionary of name → object index.
Not all data is data
If a data block contains all zeroes, we can use a little optimisation. Instead of allocating real space on the disk just to store a whole bunch of zeroes, we can instead keep a note to say “this block is all zeroes”. We don’t have to store anything then, because we can recreate it on request. This note is called a “hole”, and is what gives a “sparse file” its “sparseness”.
So here are our files again, with some holes:
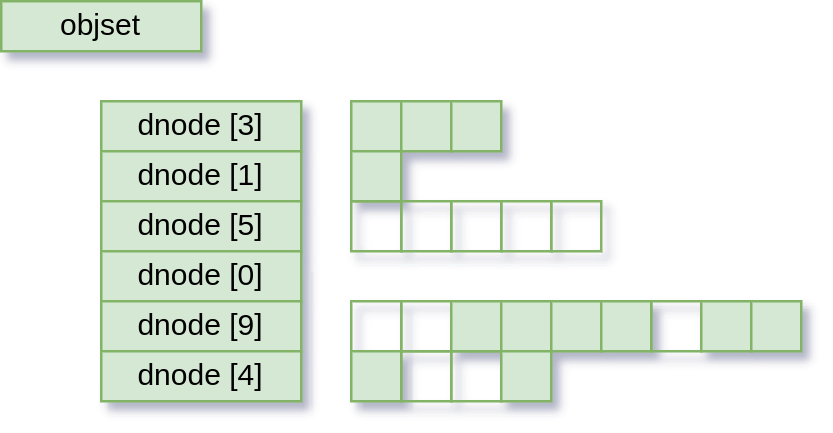
In every way, these look like they did before: the dnode still reports how many blocks they have. All that changes is that if something tries to read from one of the hole blocks, OpenZFS will create a data buffer as normal, but instead of actually going to disk and getting the data to put in the buffer, it will just zero the buffer. Less space required, fewer IO operations to spend. Lovely!
The fastest disks are memory
Unfortunately, disks are slow, even very fast ones. Memory, however, is very fast. So, when you make a change to a file, say, write some new data to the end of it, OpenZFS makes that change in memory only, and later writes it (and any other changes) down to disk. This is fast, because it only touches memory, and can make the later disk part even faster, eg your program may have written over part of a file, then written over the same part again, so when it comes to to write the change to disk, it only has to write the final state, not both changes.
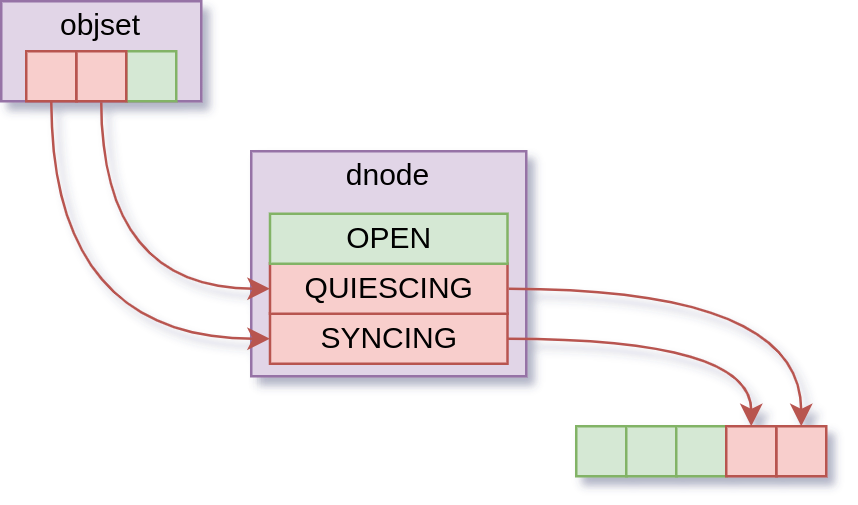
Of course, keeping changes in memory means we need extra housekeeping information to know that we have changes to write out when the time comes. We call the changed things “dirty”, and to track this, we keep some lists.
The objset has a list of dirty dnodes, and each dnode has a list of dirty blocks. So after our write, we have some nice linked lists of dirty things, ready to be written out.
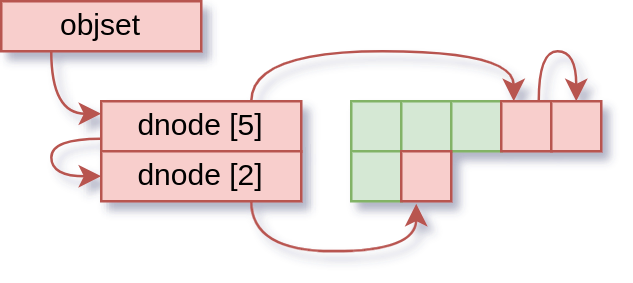
There is one crucially important detail, of course: until that data is written to disk, the version in memory is the latest, and what the application believes exists (applications don’t really know a whole lot about this disk stuff). So anything inside OpenZFS that wants to consider the current state of an object has to look at the dirty information as well, to know if its looking at the latest or not.
Data first
When it comes time to write everything out, first the blocks are written:
And then the dnodes go out, and everything is on disk.
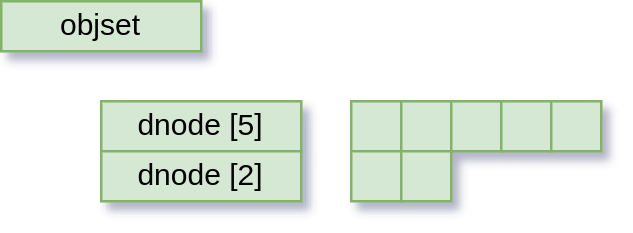
I’ve of course left out a million tiny details, not least of which is the whole copy-on-write thing. This is a useful conceptual model though; in this part of the code you can largely take for granted that the layers below you will take care of all that.
Beware of holes
The crux of this bug is around hole detection.
Sometimes an application wants to know where the holes in a file are. A file copying program is a good example: its whole job is to read all the data from one file, and write it to another. If it can find out that there’s a hole, then it saves itself the trouble of reading that block, and it also tell the filesystem to make a hole in the copy too. Even less space and fewer IO operations to think about. Extra lovely!
For a program to find out about holes, it can call lseek() with the SEEK_HOLE or SEEK_DATA options, which say “tell me the position of the next hole” or “next data”.
Holes are actually stored on disk in OpenZFS as a zero-length block pointer. There’s also a clever optimisation, which is that if a program writes a full list of zeroes, the compression system will notice and “compress” it down to a hole. However, block pointers and compression belong to the IO layer, which is quite a way away from the object layer (the DMU).
As a result, there’s no way currently to discover if a dirty block will eventually be stored as a hole. For this reason, lseek() checks if the dnode is dirty, and if so, it waits for it to be written out before it goes looking for holes.
Hidden dirt
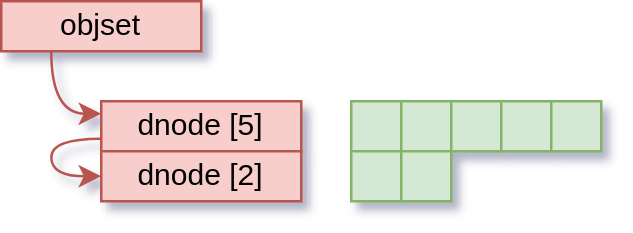
So now we come to the actual bug: the dirty check. Recall how we track dirty things:
Before we fixed it, the dirty check for lseek() used to be “is this dnode on the dirty list?”. Note that this is a subtly different question from what we actually want to know, which is “is this dnode dirty?”.
There is a moment in the dnode write process where the dnode is taken off the “dirty” list, and put on the “synced” list. This happens before the data blocks are written out, so there is a moment where the dnode looks like this:
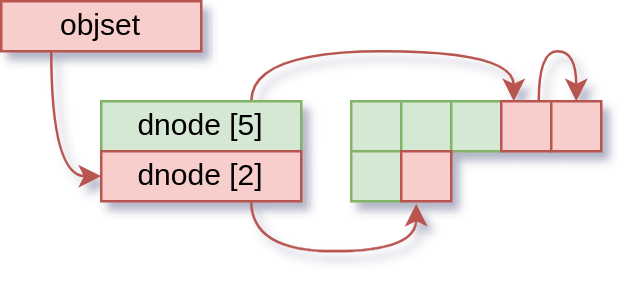
This gap is tiny. Hard to estimate, but we’re talking tens of CPU instructions. But if lseek() comes along in that moment, the dirty check fails, so it goes into the “search for data/holes” stage. And because that only sees fully allocated and written blocks, it actually sees something more like this:

And so, if a program asks about holes, it may well end up wrongly finding them in the last couple of blocks of the file.
The idea of data
Of course, the data is there, and if the program had only read it, it would have found this, but OpenZFS gave it reason to believe that it wasn’t there, so it didn’t bother.
This whole madness started because someone posted an attempt at a test case for a different issue, and then that test case started failing on versions of OpenZFS that didn’t even have the feature in question. The key part of that test was that it used the /bin/cp program from GNU Coreutils, which is almost ubiquitous on Linux systems. In v9.2 it started using lseek() to discover holes in source files.
When a new file is created, it starts life as:
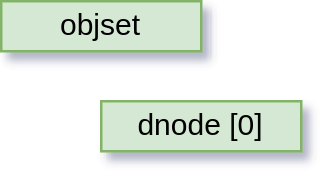
That is, just the metadata, no data.
When we add some data, it becomes:
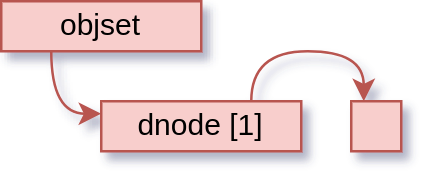
If we manage to catch it just right though, it looks like:

cp’s opening move is lseek(…, 0, SEEK_DATA), which is to say, “find the first data item from position 0”. When it works, it returns 0, because that’s where the data is. If it fails, it sets error ENXIO, that is: no data here. So cp doesn’t read, and it writes zeroes (or a hole!) to the output.
Incidentally, that’s why this isn’t “corruption” in the traditional sense (and why a scrub doesn’t find it): no data was lost. cp didn’t read data that was there, and it wrote some zeroes which OpenZFS safely stored.
The long way home
In the course of exploring the problem, we found that setting the config parameter zfs_dmu_offset_next_sync=0 defanged the reproducer. This quickly became the recommended workaround. It also brought some confusion of its own, as it appeared to improve performance, leading some to wonder if they should just leave it off permanently. It also turns out that it doesn’t actually stop the bug from occurring, just makes it vastly more difficult to hit. All this has been extremely difficult to explain, which naturally means I should expect success if I have one more go at it.
Transaction pipeline
To understand this part we need to know a little about the transaction pipeline.
At any point in time, OpenZFS has three transactions in flight:
- The OPEN transaction, which receives new changes as they arrive.
- The QUIESCING transaction, where the changes are combined and prepared to be written to disk.
- The SYNCING transaction, which is being written out to disk right now.
Once the SYNCING transaction is written, everything is moved along. QUIESCING becomes the new SYNCING, OPEN moves to QUIESCING, and a new OPEN transaction is created. There’s more details of course, but this is the basic idea.
Changes are only added to the OPEN transaction. Once it moves to the next state, it can’t be modified again. So a busy object can end up with changes on multiple transactions. And this means that when we ask “is this object dirty?”, what we’re actually asking is “is this object dirty on transaction N?” or “is this object dirty on any transaction?”
Diary of a change
Here’s a visual representation of how changes flow through the transaction pipeline. This is conceptual, of course - “clean” objects are not on any transaction, but then again, “transactions” are not a real thing either.
So lets imagine a nice normal clean object, on the current transaction.

We append a block to it, which makes it dirty in memory on the current transaction.

On the next transaction, we append another block to it. Yellow here shows the changes that aren’t on disk yet but are considered “unchanged” on this transaction.
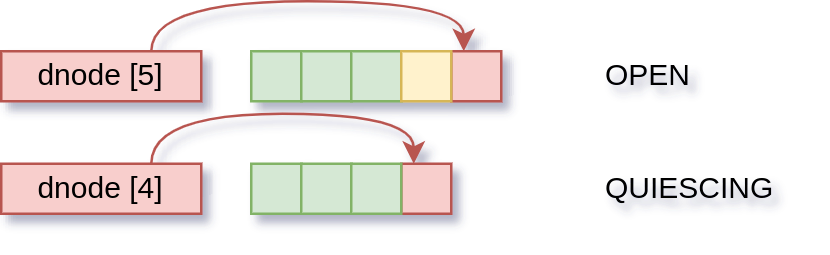
This time we don’t make any modifications, so this object is “clean” on the OPEN transaction. The first change we made is now on the SYNCING transaction, and starts getting written out.
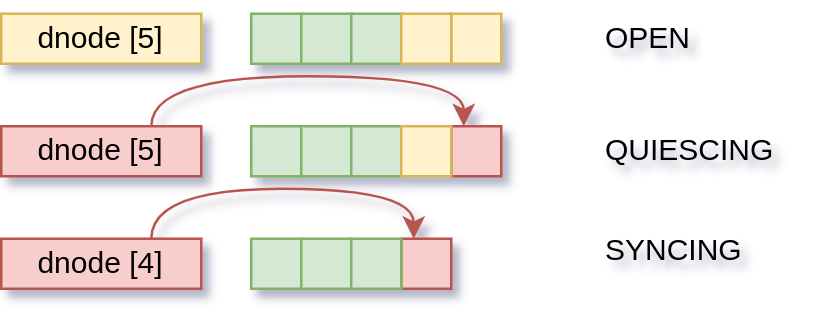
The transactions move along again and the second change starts getting written out.
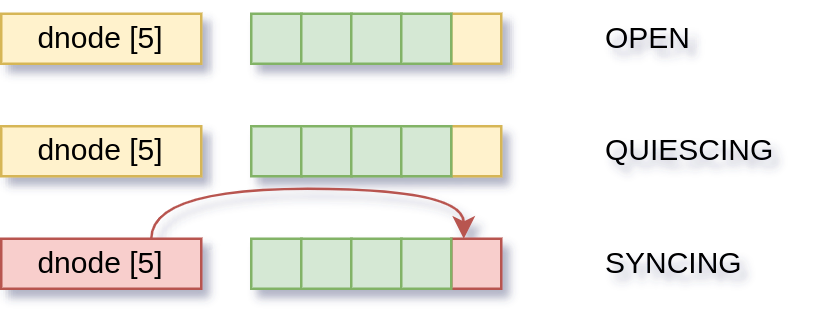
All changes are are now written.
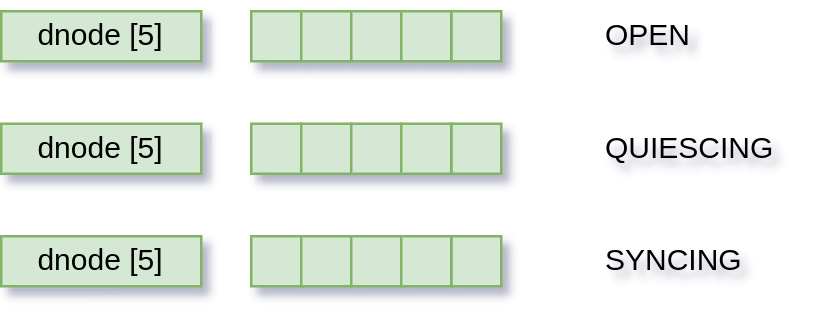
Everywhere is dirty
Earlier I wrote:
The objset has a list of dirty dnodes, and each dnode has a list of dirty blocks. So after our write, we have some nice linked lists of dirty things, ready to be written out.
But with multiple transactions in flight, we actually need a dirty dnode list and a dirty block list for each transaction, which means things actually look more like this:
This of course means the dirty check is more complex too. I wrote:
As a result, there’s no way currently to discover if a dirty block will eventually be stored as a hole. For this reason,
lseek()checks if the dnode is dirty, and if so, it waits for it to be written out before it goes looking for holes.
The user’s view of the object (via system calls like lseek() is whatever is on the OPEN transaction. Because looking for holes means looking at the on-disk state, that means we have to wait until all pending changes are on disk. So our dirty check here has to be “is this object dirty on any transaction?”, which means checking if the dnode is on any dirty list.
Wait for service
Recall that:
lseek()checks if the dnode is dirty, and if so, it waits for it to be written out before it goes looking for holes.
Even if the object is dirty only on a single transaction, that wait can be long if the pool is very busy. So OpenZFS has a config option, dmu_offset_next_sync which controls what the dmu_offset_next() function (one of the work functions implementing lseek()) does when the dnode is dirty.
If set to 0, and the object is dirty, then instead of waiting, the function simply returns an error, which causes lseek() to return “data here”. This is allowed; its always safe to say there’s data where there’s a hole, because reading a hole area will always find “zeroes”, which is valid data. It can mean a loss of efficiency, because the application can’t do special things for holes, but at least the data is always intact. And because its a simple dirty check, its fast.
If its set to 1 (the default), it will wait instead. Specifically, it will do a dirty check, and if its dirty, it will wait until the currently-syncing transaction is written out. Then it will do another dirty check; if the object is still dirty, it will return an error (and so lseek() returns “data here”), and if clean, it will go into hole detection as normal.
So now we understand the apparent performance gain with dmu_offset_next_sync=0 (it just never waits). But why does that also appear to mitigate the bug?
Doubly dirty
Recall that the bug occurs in the moment where the dnode is taken off the dirty list, but not yet put on the syncing list, and in that moment its not a list, so its erroneously considered to be clean.
Since there’s actually multiple lists, but this gap only occurs on the SYNCING list, it gives some idea of where the window you have to hit is. Its not a change “just made”, but actually made two transactions ago (from the perspective of the user). On a quiet system that can be whole seconds ago. On a busy object, with changes on multiple in-flight transactions, a single dirty check (ie dmu_offset_next_sync=0) is always going to result in “dirty”, and so lseek() returning “data here”, because even if there’s a gap on the SYNCING list, the dnode will also be on the OPEN or QUIESCING dirty lists, and so still be dirty. So the only time we can hit a gap is for the “some time later” case. Not out of the question, but incredibly difficult for any non-contrived workload (or even contrived - to my knowledge its only been seen on a quite large and unusual ARM64 system, and even then its hard to hit).
In the “wait for sync” mode (dmu_offset_next_sync=1), we have two dirty checks, and either of them can go wrong. For the first check to fail its the same as above, the “some time later” case. Its the second that is more interesting, with a wait in between.
To get the wrong answer, the dnode must only be on the SYNCING list, so that when its removed, its not on any other lists. The two dirty checks are one transaction apart, so for the second to incorrectly return “clean”, the dnode must be dirty on two consecutive transactions. That’s not hard to arrange of course, but that alone isn’t really going to make much difference.
The difference is just the timing. The first (or only) dirty check can happen any time; whenever lseek() is called. The second however is always called just the after the transaction has synced and the next one is beginning sync. The object in question is dirty there, and is removed from the dirty list and added to the syncing list before it starts syncing, which means there’s a better-than-usual chance that its happening just as dmu_offset_next() loops and does the dirty check. Overall, it raises the chances of hitting the gap and getting the wrong answer.
A clone in time
The original bug appeared to point to block cloning as being the cause of the problem, and it was treated as such until the problem was reproduced on an earlier version of OpenZFS without block cloning. This didn’t end up being the case, and it initially being blamed is perhaps a symptom of a deeper problem, but that’s for another post.
However some people did report that disabling block cloning entirely appeared to helped. So far we haven’t really found any reason why it would make a difference, other than at a distance by changing the timing - its faster to apply a clone than a write, because there’s no actual data to copy or write, so that allows more dirty dnodes and/or more transactions to be processed in a shorter amount of time. This alone means nothing, as the gap is still the same amount of time, but with other variables like hardware and workload, it could change it in the right way.
Another reason cloning was implicated was that the bug had been seen on FreeBSD. Its /bin/cp is not the Coreutils one, and doesn’t look for holes, but does call copy_file_range(), which hands off copying to the kernel to do the copy however it would like. This function has become known as “the cloning function” because the kernel might choose to service the copy via clones. However on FreeBSD it will also use lseek() under the hood to try to replicate holes in the file, and so can run into the same problem. copy_file_range() on Linux doesn’t do this, and that’s most peoples experience of cloning, leading to confusion.
That’s not to say there isn’t problems with block cloning at all - there’s a few known, which is why its currently disabled by default in OpenZFS releases. The upcoming 2.2.3 release will fix some significant issues with block cloning, and a comprehensive test suite is coming together. How block cloning became the whole thing it is, and the interaction with this and other issues in the public perception, is something I want to write more about, but this has gone on long enough.
History of a bug
This bug has a long history, as can be seen by reading multiple earlier patches that made changes around it. All had seen something wrong, but hadn’t fully understood it.
- Nov 2021:
de198f2Fix lseek(SEEK_DATA/SEEK_HOLE) mmap consistency - May 2019:
2531ce3Revert “Report holes when there are only metadata changes” - Mar 2019:
ec4f9b8Report holes when there are only metadata changes - Nov 2017:
454365bFix dirty check in dmu_offset_next() - Mar 2017:
66aca24SEEK_HOLE should not block on txg_wait_synced()
The proto-bug seems to go back even further, to a 2006 commit in early Sun ZFS. Among other changes, we see:
diff --git usr/src/uts/common/fs/zfs/dmu.c usr/src/uts/common/fs/zfs/dmu.c
index f883842dad..8119f1901f 100644
--- usr/src/uts/common/fs/zfs/dmu.c
+++ usr/src/uts/common/fs/zfs/dmu.c
@@ -1638,7 +1638,7 @@ dmu_offset_next(objset_t *os, uint64_t object, boolean_t hole, uint64_t *off)
* we go trundling through the block pointers.
*/
for (i = 0; i < TXG_SIZE; i++) {
- if (dn->dn_dirtyblksz[i])
+ if (list_link_active(&dn->dn_dirty_link[i]))
break;
}
if (i != TXG_SIZE) {
This is where it changed the dnode dirty check from checking a property of the dnode itself to checking if the dnode was present on an external list. That alone is not a bug; it might be that there’s something else preventing the off-list gap being hit (eg another lock), so maybe the bug was never in this version of ZFS. What has changed is that its no longer possible to understand the dirty state directly; its now reliant on what’s happening elsewhere in the system.
I’m not really blaming anyone - complex problems sometimes require complex solutions! Its just one of those things that the details of are long forgotten, so its on the reader to make sure they understand it, without much external guidance. There’s more to say about this, but not here.
Turn tape over
In the end its not a data corruption bug as such, but possibly that’s splitting hairs. As you see though, it has existed a long long time, and is fiendishly difficult to hit in almost all real-world scenarios, and even harder to hit undetected. It does reinforce the standard mantras about storage though: take backups, test your backups.
I’ll never exactly be happy about a data-loss bug, but what I am happy about is the way that a whole group of people appeared over a holiday weekend and worked together to solve an ancient mystery. I loved being a part of it, and I’m now looking for ways to get that happening in more proactive and less desperate situations.
That’s all for now. Hopefully more soon about all the other thoughts I had while working on this!
SPONSOR MY WORK
Use OpenZFS? Like this post? Help out by sponsoring my OpenZFS work!